Vibe Coding 实战:三天,一个人,一个 Claude Session Viewer——给三家 AI CLI 当统一会话浏览器

前言:五月那个周末,我同时挂着 Claude Code、Codex、Gemini CLI 三个窗口。想翻一段两天前调通的 prompt,结果在 ~/.claude、~/.codex、~/.gemini 三个目录里 grep 了二十分钟。
气得我直接跟 Claude Code 说:"我要写个桌面 App,统一翻这三家的会话。"
三天之后,v0.1.0 发出去了,5500 行 Rust + 大概 8000 行 Vue/TS,macOS、Windows、Linux 三平台安装包都打好了。
这篇是我这三天的真实记录,重点不在介绍这个工具是什么,而在我具体怎么跟 Claude Code 合作把它从零搓出来。希望对正在 vibe coding 的你有点参考。
仓库在这:https://github.com/jerrywu001/cc-sessions-viewer
先抛结论:Claude Code 帮你解决的是"懒得写第一版"
这三天最大的体感是,Claude Code 救的不是我不会写,是我懒得写第一版。
我熟 Vue,也写过 Tauri,但让我从零手敲 Rust 的 JSONL 解析、Tauri 命令、Vue 前端、三种主题、i18n、测试,我可能磨蹭一个月。让 Claude Code 干,三天能跑出一个像样的 MVP,前提是我得知道每一步要给它什么,以及哪里必须我自己拍板。
技术栈选型:我没让它替我决定
正经事开始之前,我先把栈定了:Tauri 2 + Vue 3 + Rust,前端 TypeScript。
为什么不让 Claude Code 帮我选?因为这事它会保守。问它"我要做个桌面 App 选什么栈",它大概率给你 Electron + React,因为这是它训练数据里最常见的组合。
但我清楚我要什么:
- 安装包要小。Electron 起步就是 100M+,Tauri 能压到 10M 以内。
- 文件 IO 要快。读 100M+ 的 JSONL 走 Node 那一套 stream 很难看,Rust 直接
BufRead::lines()干净。 - 前端我熟 Vue,不想为了"AI 更熟" 切到 React。
栈一旦定下来,Claude Code 会非常听话地在这个栈里给你写。选型这种"半小时决定影响三个月"的事,自己拍板就好。
Day 1:跑通最小闭环,第一晚只要"能看见聊天"
第一天的目标很纯粹:给定 Claude Code 的某个 JSONL 文件,能在 Tauri 窗口里把对话渲染出来。
我没让它一上来就规划整个项目结构,只丢给它一句:
"读
~/.claude/projects/-Users-wuchao-apps-claude-session-viewer/<某个真实 sessionId>.jsonl,告诉我它的 schema,每一行是个什么。"
让它先去理解数据,而不是先写代码。它读完之后给我整理出来:
- 每行一个 JSON object,
type字段区分user/assistant/summary等 - assistant 行的
message.content是个数组,里面混着text/thinking/tool_use三种 block - user 行也可能是个数组,里面装的是
tool_result,要按tool_use_id配对回去 - 一个 session 里可能多次出现
tool_use→tool_result,要保持顺序
这一步我没让它写一行代码。先把数据吃透,再让它写解析,剩下的 bug 会少很多。
然后下一个 prompt:
"在 src-tauri 里加一个 Tauri 命令
read_session(path) -> Vec<Block>,按上面的 schema 解析。Block 用一个 enum,每种 kind(text / thinking / tool_call / tool_result / image)一种 variant。"
它写了第一版,我跑起来,三处问题:
thinkingblock 没正确识别,它把type: "thinking"当成了普通 text。- tool_use 和 tool_result 配对错位,它没考虑跨 message 配对。
- 文件大的时候卡住,它一次性
serde_json::from_str整个文件。
第一个我让它修,五分钟搞定。
第二个我自己读了一遍它的代码,发现它在用一个 HashMap 按 tool_use_id 做关联,但 key 取错了字段。我直接指出来:"你 line 87 应该取 block.id 不是 message.id",它认错改对。
第三个,我让它改成按行读、按行解析,整个文件用 BufRead::lines() 流式跑。这是 Rust 的常识,但它一开始没主动用。
这一晚我学到的事是别怕小步快跑。我宁可跟它来回十次 prompt 把一个命令打磨好,也不让它一次性产出五个命令然后我挨个调试。一次只让它做一件事,错了立刻发现。
第一天结束时,能看到这个画面:
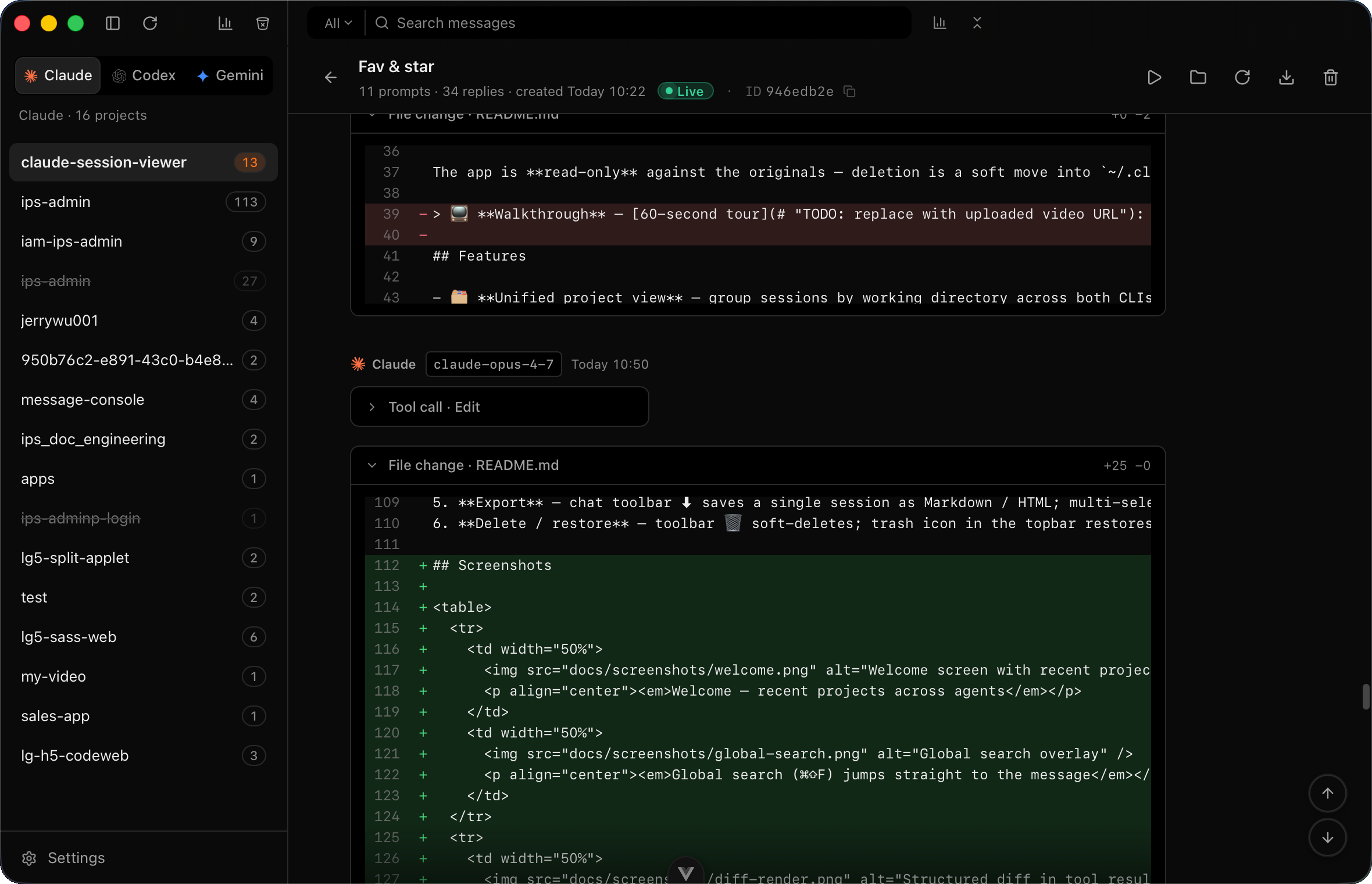
Thinking 块、tool 调用、structured diff 都能渲染。Claude Code 写代码改自己代码这件事,居然挺顺。
Day 2:让产品像个产品(搜索、导出、i18n)
第二天我列了三件事:session 内搜索、导出 Markdown/HTML、i18n 自动识别系统语言。
这三件事都不需要碰后端的核心解析,纯前端加一些工具函数。完美的"丢给 Claude Code 自己干"的任务类型。
我的策略变了:每个 feature 配一个独立的 ts 模块加一个 vitest 测试文件,让它一次产出一对。
举个例子,session 内搜索:
src/chatToolbar.ts // 搜索、定位、scope 过滤纯函数
test/chatToolbar.test.ts // 单元测试
src/components/ChatToolbar.vue // 只负责 UI + 调上面的纯函数
我给它的 prompt 大致是:
"我要在打开的 session 里做搜索。功能:输入关键词,命中后高亮、按 ↑ ↓ 在命中之间跳。还要有 scope:全部 / 仅用户消息 / 仅 AI 回复 / 仅工具输出。
帮我先把纯逻辑写成
chatToolbar.ts,导出findMatches(blocks, query, scope) -> Match[]。同时写test/chatToolbar.test.ts,覆盖空 query、跨 block 命中、scope 过滤、unicode、大小写不敏感这几种情况。UI 单独的 Vue 文件,下一步再做。"
它给了两个文件,测试一跑过了 11 个 case,错 2 个。我让它修,再跑通。然后才进 UI。
为什么这样做?因为 vitest 是我能信得过的"Claude Code 体检"。测试通过的纯函数,UI 怎么写都不会写崩。让它自己写测试再让它自己跑过,比我盯着每一行 review 高效十倍。
到 Day 2 结束,前端已经积累了一堆这种纯函数模块:
format.ts时间格式化chatToolbar.ts会话内搜索export.tsMarkdown / HTML 导出i18n.ts多语言加自动识别settings.ts主题 / 语言持久化到 localStorage
每个都配 vitest。这一晚还顺手把导出做了:
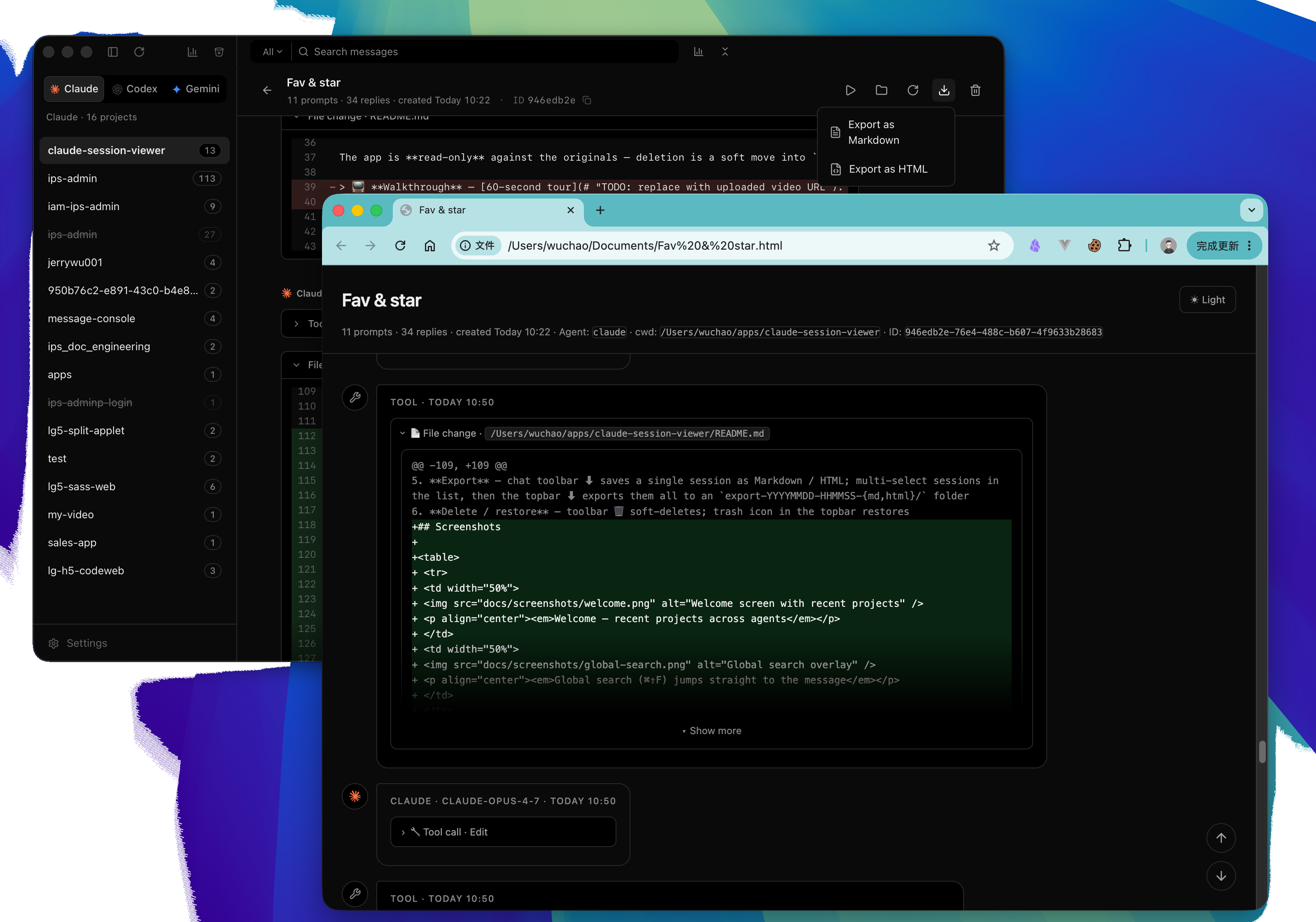
HTML 导出有个细节我特别得意,头像、CSS 全部 inline 进单文件,离线打开任何浏览器都能看,不依赖任何外链。这个想法是 Claude Code 提的,我原本只想丢一个 link。它说:"你既然导出是给以后归档用,那应该假设没有网络。" 我立刻同意。
Vibe coding 里很值钱的一类对话是 AI 反过来 challenge 你的需求。别打断它,让它说完。
Day 3:把抽象做正,把测试补齐
第三天最关键的一件事是让架构能扩展。我已经知道下一步要接 Codex 和 Gemini CLI,所以这一天的目标:把"Claude Code 专属"的代码逻辑全部抽到一个 trait 后面。
我没让 Claude Code 一上来设计 trait,而是先让它做一件事:
"在不写一行代码的前提下,对比 Claude Code 和 Codex 两家会话的存储方式。
Claude 的我已经在
agents/claude.rs实现了。Codex 的你去读~/.codex/sessions/2026/05/15/rollout-xxxx.jsonl第一行到第五十行,告诉我:
- 目录布局怎么映射到 project?
- user 消息和 AI 消息分别长什么样?
- 图片怎么记录?跟 Claude 有什么不同?
- 如果要做'按项目 group',project 的 key 应该从哪里取?"
它的回答让我对 Codex 的怪异 schema 有了清晰的认知:
Codex 把图像放在
response_item.message里(role=user, content 里有input_image),但同一个用户输入的纯文本却放在另一条记录event_msg.user_message里。两条记录共享同一个id字段。如果直接渲染会出现"用户发了两次消息"。
这就是关键的认知。然后我让它设计 trait:
"现在你已经知道 Claude 和 Codex 的差异。设计一个
SessionSourcetrait,让加 Gemini 这类新 agent 的成本变成『加一个文件 + 加一个 match 分支』。哪些方法该上 trait,哪些应该留在共享 util?"
它给了一版设计,我改了三处:
list_projects/list_sessions/read_session上 trait,这是核心。- 回收站(trash)我让它留在 trait 之外,因为所有 agent 的 trash 文件都用同一种
.metasidecar 格式,目录都在~/.claude/.session-viewer-trash/,没必要每家重新写一遍。 image_src(block) -> Option<String>上 trait,因为这正是 Claude / Codex / Gemini 三家分歧最大的地方。
最后我在 agents/mod.rs 顶上写了那段注释:
// 接入新 agent(如 gemini)的步骤:
// 1. 新建 `agents/<name>.rs`,定义一个 unit struct...
// 2. 在文件末尾 `pub mod <name>;` 声明 module,并在 `source()` 里加一个 match 分支。
// 3. 前端 `types.ts` 的 `Agent` 联合类型里加上 `"<name>"`...
//
// 不要把 agent-specific 的解析细节漏到 lib.rs 或 trash.rs —— 加 agent 应该是
// 一个文件加一个 match 分支,超出这个范围就说明 trait 的抽象出了问题,需要重新设计。
这段注释是写给未来的 Claude Code 看的。CLAUDE.md 和源码顶部注释就是 AI 长期协作的"项目宪法",写得越具体,AI 越不会在第二个月把抽象做歪。
到 Day 3 收尾,第四天接 Gemini CLI 的时候,从 0 到能跑通只花了不到两小时。trait 抽象的回报立刻兑现。
第四天放出去那一刻,搜索和回收站长这样
虽然题目说"三天 MVP",第四天我打了 release pipeline 把 v0.1.0 发出去了。这里放两张那时候的截图,证明前面三天的架构投资是值的:
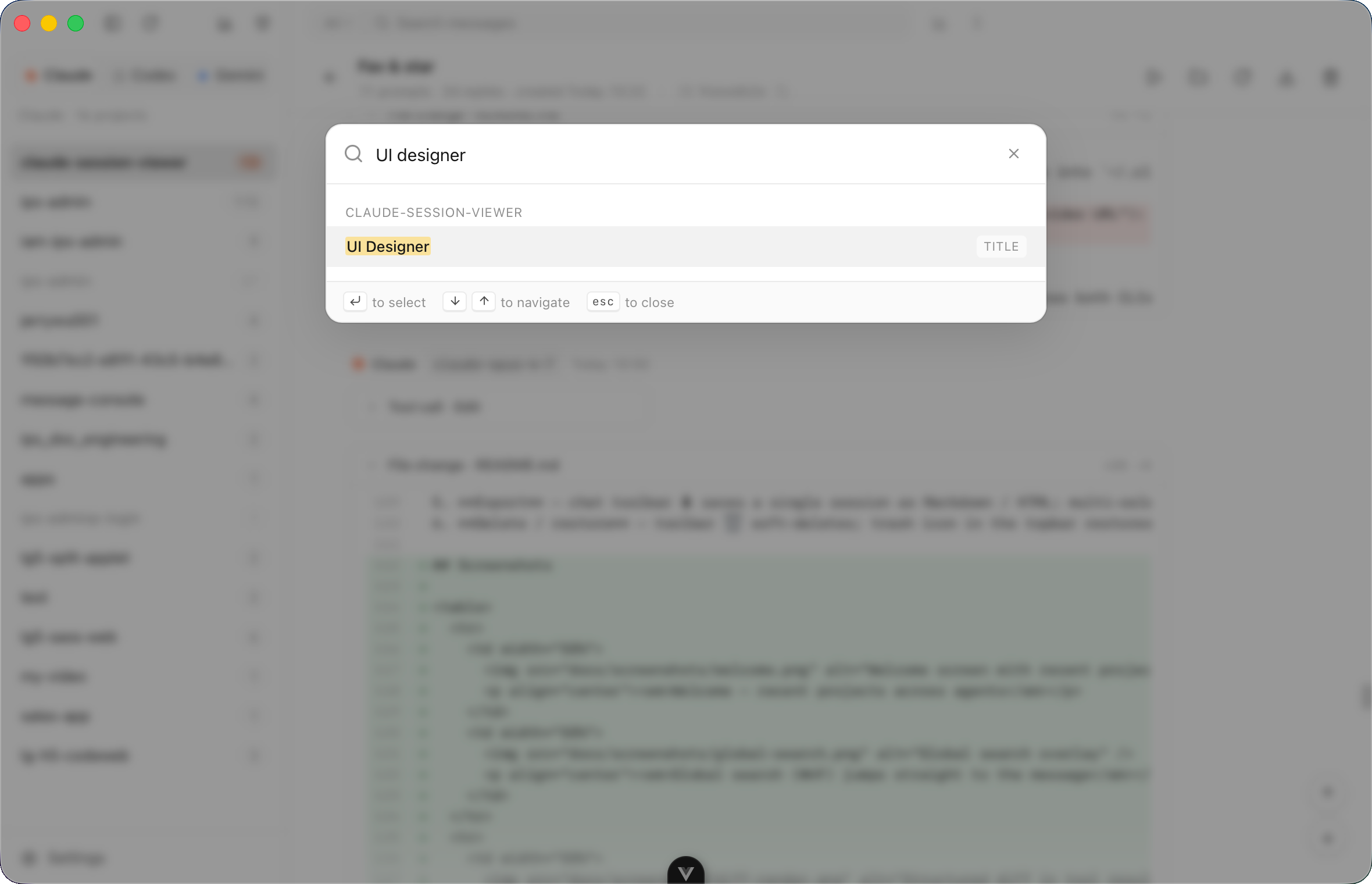
⌘⇧F 全局搜索的弹窗,纯前端组件,但搜索结果是 Rust 后端跑的。靠的是 Day 3 抽好的 trait:search_sessions(agent, query) 直接 dispatch 到对应 agent 的 source。
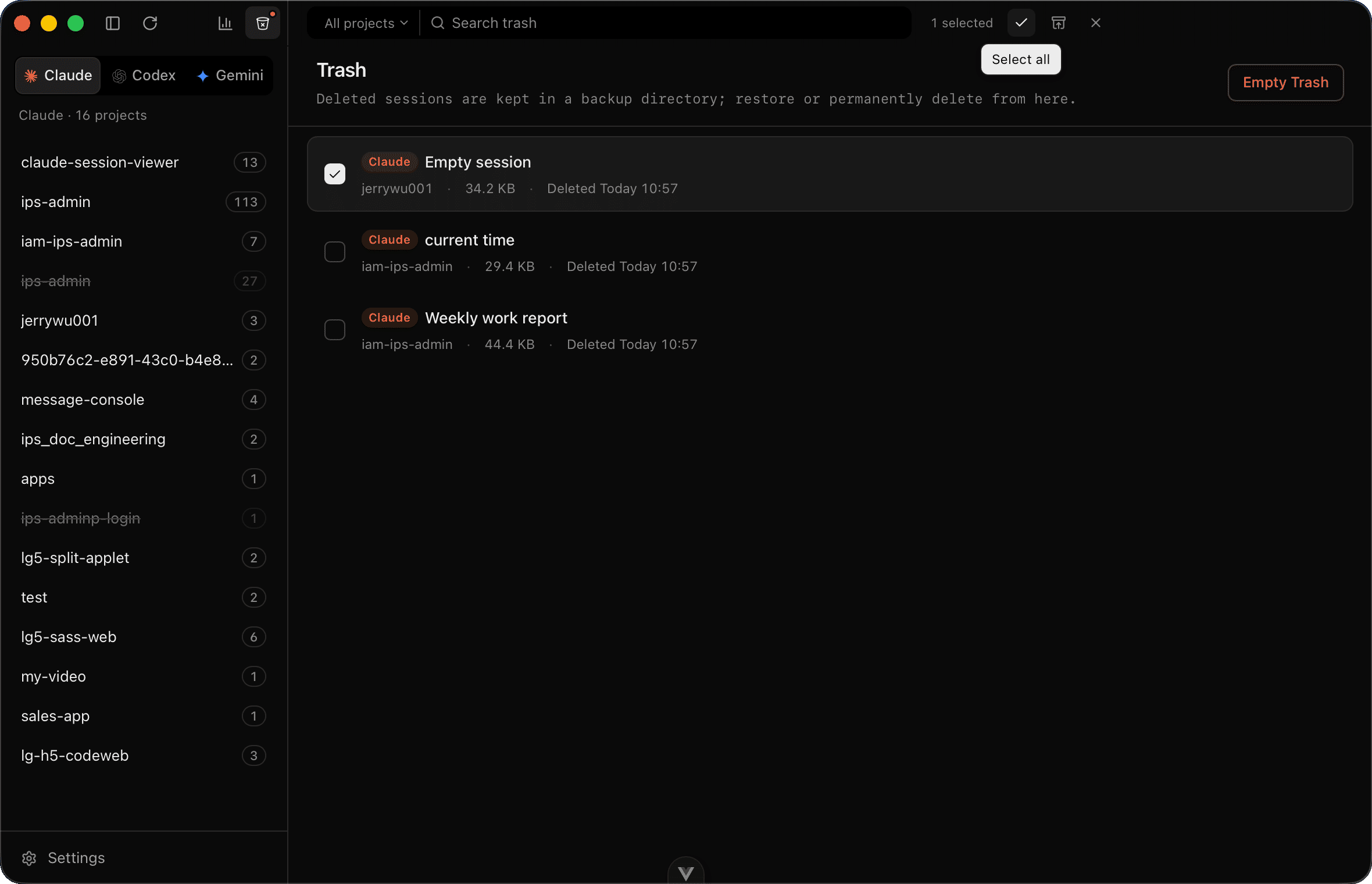
Trash 是跨 agent 共享的。删 Claude 的会话和删 Codex 的会话扔进同一个回收站,恢复时按 .meta 里记录的原始路径还原。
后来 v0.1.2 我加了统计面板,能按项目、模型、工具切片看 Token 花费:
这一块用了 AntV G2 画的图。从加 Tauri 命令到接前端图表,Claude Code 写完我大概只动了 20 行调样式。底子抽象做对了,后面每个 feature 都是顺水推舟。
我反复验证有效的几条 Claude Code 协作经验
下面这几条不是套话,是这三天我反复验证有效的:
1. 让 AI 先理解数据/系统,再写代码
最重要的一条。直接让它写代码,它会脑补一个"最常见的 schema",然后你花一晚上调那些脑补出来的字段。让它先读真实文件、读真实接口、读真实日志,再让它动手。
2. 一次只做一个文件的一层抽象
不要让它一把梭"完整 feature"。把任务切成"纯函数加测试"、"trait 加一个实现"、"组件加它依赖的纯函数",每一刀切下去都能被 vitest 或 cargo check 立刻验证。错了立刻知道,比一锅炖之后挨个 debug 省太多时间。
3. 测试是给 AI 的护栏,不是给人看的
我不会手写测试给它,我让它自己写测试。但写完之后我会扫一眼 case 完不完整。如果测试覆盖太薄,我就让它补:"补一下空输入、unicode、边界值这三类"。测试一过,我就敢让它在那个模块上继续叠功能。
4. CLAUDE.md 比 prompt 重要
你跟它每次对话里讲的"风格、约束",下一次开新会话就全丢了。把项目级别的约定写进 CLAUDE.md,每次都自动加载,比每次 prompt 里重复有效百倍。
我那个项目的 CLAUDE.md 现在大概 200 行,写的是"agent 抽象的边界"、"trash 不要做 agent-specific 分支"、"resume 的 session id 必须 allowlist 校验"这种架构约定,不是写代码风格。
5. 品味这一层必须你自己留着
命名、UI 的微妙手感、什么时候停止加新 feature,这些 AI 做不好。它能让你三天产出 30 个特性,但它分不清哪三个是真痛点。
我 v0.1.0 砍掉了一堆它已经写好的代码:生成 PDF、CSV 导出、命令面板,看了一遍觉得没必要,会让 MVP 变臃肿。删掉的代码一点都不可惜。stop 的判断必须你来。
6. 让它 challenge 你
我有时候会主动加一句:"如果你觉得这个需求有问题,先说。" 然后它真的会反驳。
那次导出 HTML 它建议 inline 所有资源;trait 设计那次它告诉我 trash 不该上 trait。这些 challenge 比它写代码本身更值钱。
后续 & 一些没写进 MVP 的坑
发完 v0.1.0 之后我才碰到一些更细的问题,简单提一下,给后人避坑:
macOS 红绿灯按钮和自定义 titlebar 同时存在的问题。我想要 40px 高的 unified 顶栏,侧栏背景一直延伸到顶,但 macOS 原生按钮总是落在标题栏正中。试过 setFrameOrigin 手动挪,肉眼好看了,但拖拽时窗口的 click-drag tracking 被破坏。最后找到的"非黑魔法"解法是在窗口上挂一个空的 NSToolbar 并设 unifiedCompact 风格,AppKit 会自动把 titlebar 撑到刚好 40px。这个是看 AppKit 源码注释看出来的,Claude Code 不知道,但你把发现讲给它听之后它能立刻写出 Rust 实现。
osascript 调 Terminal 的命令注入风险。resume_session 是拼接 shell 命令丢给 osascript 的,session id 来自前端。我让 Claude Code 加了一个严格的 allowlist 校验:^[A-Za-z0-9-]+$,拒绝一切奇形怪状的 id。这种安全细节只有你提它才会做,默认它不主动加。
Codex 的 image/text 分开存储。前面提过,最后的解法是在 agents/codex.rs::read 里 buffer 住所有 image block,碰到下一条 event_msg.user_message 时拼回去。这是非常 agent-specific 的脏活,绝对不应该漏到上层。trait 设计对了之后,这种脏活全埋在文件内部。
写在最后
三天的成本:周末两天加周一晚上。我写代码的时间大概一共 14 小时,其中至少 10 小时是在跟 Claude Code 来回对话和审它的代码,真正自己手敲的部分只有红绿灯按钮那段 Objective-C / Rust 黑魔法、几处 CSS 微调、和 CLAUDE.md。
发出去之后这周加了实时刷新(live tail)、Token 统计、Linux 打包,到现在 v0.1.2,5500 行 Rust + 完整测试套件 + 三平台安装包。
我对这种工作流的看法是,它不让你变成超人,它让"我懒得做"和"我做不出来"变成同一件事。你愿意推动它一步,它就给你一步的产出。你停下来,它也跟着停。AI 是放大器,不是替代品。
工具是开源的,MIT,仓库地址:https://github.com/jerrywu001/cc-sessions-viewer
如果你也是三家 CLI 都在用、被会话散落折磨过的人,欢迎下载试一下;觉得哪里不顺手直接开 Issue。想接 aider / opencode / cursor-agent 进来的,PR 通道也是开的,加一个 agent 真的只需要新建一个文件加一个 match 分支。
下一篇打算写一下 v0.1.0 到 v0.1.2 这一周加 Token 统计的过程,重点讲后端怎么聚合 12 万行 JSONL 跑出秒级响应。感兴趣的话点个赞催更。